树的遍历算法
二叉树的遍历分为 广度优先(BFS) 和 深度优先(DFS) 两种,其中 DFS 又分为前序、中序、后序遍历。这 4 种遍历方式是算法的基础,动态规划、回溯等高级算法都依赖于此。

Binary Tree BFS
|

Binary Tree DFS
|
遍历方式对比
| 遍历方式 |
顺序 |
特点 |
实现 |
应用场景 |
| 广度优先遍历(BFS) |
层序遍历 |
按层从上到下、从左到右依次访问每一层的节点 |
队列 |
树的深度、宽度、层、最短路径 |
| 前序遍历(DFS) |
根-左-右 |
自顶向下 从根节点到叶子节点传递信息 |
递归/栈 |
复制树、序列化、路径查找 |
| 中序遍历(DFS) |
左-根-右 |
纵向一条线从左向右扫描。最难,最常考,专用于 BST |
递归/栈 |
BST 有序输出、验证 BST |
| 后序遍历(DFS) |
左-右-根 |
自底向上 从叶节点到根节点返回信息 |
递归/栈 |
树的深度/高度、直径、删除树、最近公共祖先 |
BFS vs DFS

BFS: 横向扩散,逐层遍历
|

DFS (前序遍历): 纵向深入,一条路走到底
|
核心区别:
-
BFS:从根节点向四周扩散,逐层遍历,类似水中的波纹
- 适合求最短路径(在无权图中,BFS 找到的路径一定是最短的)
- 空间复杂度 O(w)(w 为最大宽度),对于完全二叉树,空间开销远大于 DFS
-
DFS:纵向深入,沿着一条路径走到底,再回溯探索其他路径
- 空间复杂度 O(h)(h 为树高),对于平衡树更优
- 适合求深度、高度、路径问题
DFS 的实现方式
递归实现
递归解法可以分为两类思路:
- 遍历思路:遍历整棵树,在遍历过程中更新外部变量或执行操作(类似回溯算法的思维)
- 分解思路:将问题分解为子问题,通过子问题的解推导出原问题的解(类似动态规划的思维)
递归 -> 下地下室取东西
如果我们把递归的过程想象成去地下室每层房间取东西,那么就有三种情况:
- 下去时打包好带上 → 前序遍历
- 下去时打包好,上来时带上 → 中序遍历
- 触底返回时打包好带上 → 后序遍历
| func traversal(root *TreeNode) []int {
if root == nil {
return []int{}
}
// Preorder: 根 -> 左 -> 右
// nums := []int{root.Val}
// nums = append(nums, traversal(root.Left)...)
// nums = append(nums, traversal(root.Right)...)
// Inorder: 左 -> 根 -> 右
nums := traversal(root.Left)
nums = append(nums, root.Val)
nums = append(nums, traversal(root.Right)...)
// Postorder: 左 -> 右 -> 根
// nums := traversal(root.Left)
// nums = append(nums, traversal(root.Right)...)
// nums = append(nums, root.Val)
return nums
}
|
递归的本质
在 DFS 的遍历中,前、中、后指的是根节点的位置。递归解法更容易理解和编写,因为直接调用了系统栈,而迭代解法则是在手动维护栈结构,控制节点入栈/出栈顺序。
快速排序就是前序遍历,归并排序就是后序遍历。
迭代实现
颜色标记法(通用模板)
颜色标记法通过调整入栈顺序即可通杀前、中、后序遍历:
| const (
WHITE = 0 // 未访问
BLACK = 1 // 已访问
)
type ColorNode struct {
Color int
Node *TreeNode
}
func iterative(root *TreeNode) []int {
nums := []int{}
stack := []ColorNode{{WHITE, root}}
for len(stack) > 0 {
cn := stack[len(stack)-1] // cn is colorNode
stack = stack[:len(stack)-1]
if cn.Node == nil {
continue
}
if cn.Color == WHITE {
// 前序的压入顺序:右-左-根(BLACK)
// stack = append(stack, ColorNode{WHITE, cn.Node.Right})
// stack = append(stack, ColorNode{WHITE, cn.Node.Left})
// stack = append(stack, ColorNode{BLACK, cn.Node})
// 中序的压入顺序:右-根(BLACK)-左
stack = append(stack, ColorNode{WHITE, cn.Node.Right})
stack = append(stack, ColorNode{BLACK, cn.Node})
stack = append(stack, ColorNode{WHITE, cn.Node.Left})
// 后序的压入顺序:根(BLACK)-右-左
// stack = append(stack, ColorNode{BLACK, cn.Node})
// stack = append(stack, ColorNode{WHITE, cn.Node.Right})
// stack = append(stack, ColorNode{WHITE, cn.Node.Left})
} else {
nums = append(nums, cn.Node.Val)
}
}
return nums
}
|
后序遍历的特殊处理
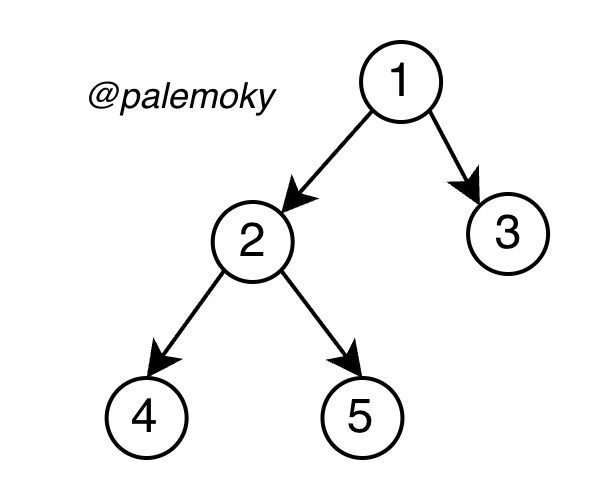
相比前序和中序,后序遍历的迭代实现最复杂。它是在中序遍历的基础上增加了一个核心判断:只有当右子树为空或已被访问过时,才访问根节点。
核心判定公式:curr.Right == nil || curr.Right == prev
prev:记录上一个 刚刚访问过 的节点,防止在回溯过程中反复进入右子树- 在后序遍历中,
prev 的作用类似于回溯算法中的 used[] 标记位
示例:以 [1,2,3,4,5] 为例,观察节点 2 的两次"路过"
第一次路过节点 2:准备检查右子树
| Go 伪代码 |
|---|
| // 栈路径:1 -> 2 -> 4 -> (回到) 2
stack = [1, 2]
curr = 2
prev = 4 // 刚刚访问完左子树的叶子 4
// 判定逻辑
if curr.Right == nil || curr.Right == prev {
// 2.Right 为 5,prev 为 4
// 不满足条件:右子树 5 还没看呢!
} else {
curr = curr.Right // 转向右子树 5,节点 2 继续留在栈中等待
}
|
第二次路过节点 2:子树全部处理完,最终访问
| Go 伪代码 |
|---|
| // 栈路径:1 -> 2 -> (转向) 5 -> (回到) 2
stack = [1, 2]
curr = 2
prev = 5 // 刚刚访问完右子树的叶子 5
// 判定逻辑
if curr.Right == nil || curr.Right == prev {
// 2.Right 为 5,prev 为 5
// 满足条件:右子树已经处理过了,现在可以放心访问 2 了
nums = append(nums, 2)
prev = 2 // 标记 2 已访问
stack = [1] // 弹出 2
curr = nil // 继续向上回溯
}
|
DFS 的四种解题模式
|
自顶向下(Top-down) |
自底向上(Bottom-up) |
| 递归 |
递归 + 自顶向下(最常用)
特征:
• 状态通过参数往下传
• 在进入节点时处理逻辑
• 不依赖子树返回值
典型题目:
• 路径和
• 路径字符串
• 根到叶子的约束判断
判断口诀:
"我到这一步时,已经知道所有祖先信息" |
递归 + 自底向上(第二常用)
特征:
• 子问题先算
• 通过返回值往上传
• 后序遍历语义
典型题目:
• 树高度
• 是否平衡二叉树
• 最大路径和(经典)
判断口诀:
"我得先知道左右子树怎么样,才能算我自己" |
| 迭代 |
迭代 + 自顶向下
特征:
• 显式栈(模拟递归)
• 入栈时携带状态
• 弹栈即处理
典型场景:
• 避免递归栈溢出
• 需要手动控制遍历过程
• 前序/中序遍历的迭代实现
本质:
可以等价于"递归 + 自顶向下" |
迭代 + 自底向上(最难)
特征:
• 模拟后序遍历
• 常用:双栈 / 标记法
• 状态在"回溯阶段"处理
典型题目:
• 后序遍历
• DP on Tree 的迭代版
难点:
需要手动模拟递归的回溯过程 |
Note
动态规划包含自顶向下的记忆优化递归和自底向上的迭代填表。
扩展应用
链表的后序遍历
如果要倒序打印单链表上的所有节点的值,可以采用后序递归操作:
| func reversePrint(head *ListNode) []int {
if head == nil {
return []int{}
}
return append(reversePrint(head.Next), head.Val)
}
|