递归
对于大多数人来说,递归非常难以理解,因为人脑的限制,当我们思考递归过程时,非常容易“爆栈”。不过,我们可以通过下地下室取东西来类比递归:
- 我们从地面开始下地下室,每到达一层都有 3 种选择:
- 把东西打包好带上 → 前序遍历(已知当前层,未知后续层)
- 先把东西打包好,等到返回地面时再带走 → 中序遍历(仅限 BST)
- 在触底返回时打包带走 → 后序遍历(已知所有走过的路)
- 触底时开始返回
- 返回地面时,我们取回所有所需物品,递归结束。
在这个过程中,我们在每层重复的动作就是递归中的最小重复单元(这就是我们编写的递归代码),而触底返回,就是递归的终止条件。所以我们编写递归时,只要抓住了最小重复单元和终止条件,递归就迎刃而解了。
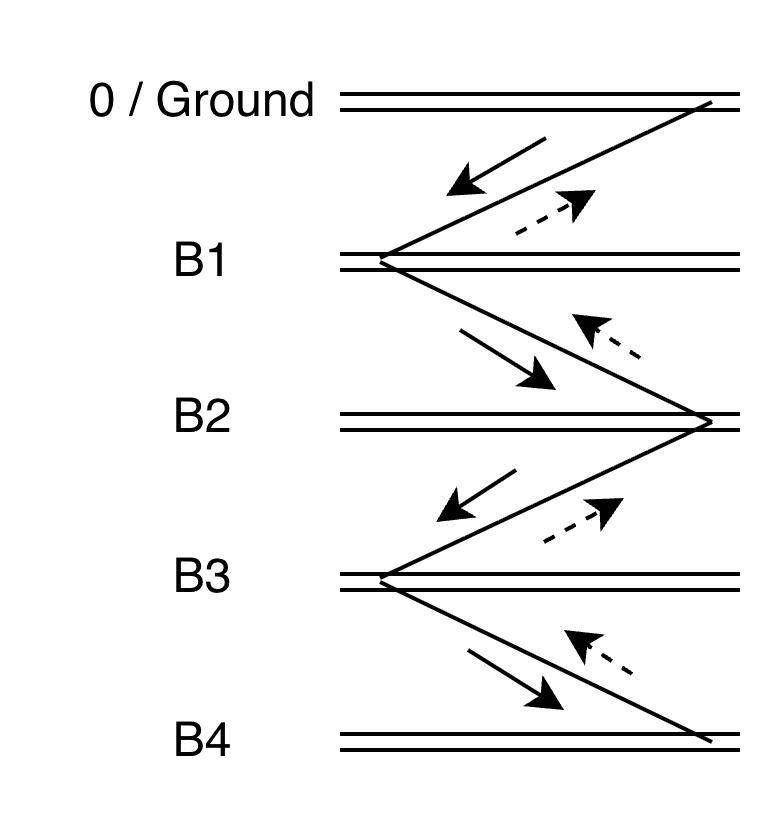
递归的地下室类比
|
🕳️ 地面
└─ 👣 第 1 层:factorial(3)
└─ 👣 第 2 层:factorial(2)
└─ 👣 第 3 层:factorial(1)
└─ 🎯 触底:factorial(0)
↓
┌─ ✅ 返回 1(终止条件)
┌─ 🔙 返回 1 × 1 = 1
┌─ 🔙 返回 2 × 1 = 2
┌─ 🔙 返回 3 × 2 = 6
🌟 最终结果:6
3! 递归调用栈示意图
|
常见的递归场景:
如何写出递归?
递归的本质是将大问题拆解为相似的小问题。编写递归时,可以遵循以下“三部曲”:
- 明确函数定义(状态与目标):确定函数的输入参数代表什么“状态”,以及返回值代表什么的“解”。
- 寻找终止条件(Base Case):确定递归什么时候“触底”——即在最简单的情况下,不需要再递归就能直接得到答案。
- 寻找递推关系(子问题分解):确定如何利用子问题的解来合成当前问题的解。即:
f(n) 和 f(n-1) 之间有什么逻辑关系?
Tip
只要递归状态从 0 开始,数组就要多开 1 个以避免越界访问,如动态规划和前缀和。
经典题目
实战应用:扁平列表转树形结构
在实际业务中,数据库通常以扁平结构存储层级数据(如省市区、部门组织),每条记录通过 parent_id 指向父节点。API 层需要将其重组为树形结构以供前端渲染。这是递归在工程中最典型的应用场景之一。
数据结构定义如下:
| type Area struct {
ID int `json:"id"`
ParentID int `json:"parent_id"`
Name string `json:"name"`
Level int `json:"level"`
Children []*Area `json:"children,omitempty"`
}
|
测试数据:
| flatData := []*Area{
{ID: 1, ParentID: 0, Name: "广东省", Level: 1},
{ID: 2, ParentID: 0, Name: "浙江省", Level: 1},
{ID: 3, ParentID: 1, Name: "广州市", Level: 2},
{ID: 4, ParentID: 1, Name: "深圳市", Level: 2},
{ID: 5, ParentID: 2, Name: "杭州市", Level: 2},
{ID: 6, ParentID: 3, Name: "天河区", Level: 3},
{ID: 7, ParentID: 3, Name: "番禺区", Level: 3},
{ID: 8, ParentID: 6, Name: "猎德街道", Level: 4},
{ID: 9, ParentID: 8, Name: "猎德村", Level: 5},
}
|
方法一:递归(\(O(n^2)\))
思路直观:对每个节点,递归地从整个列表中筛选出其子节点,直到叶子节点为止(Base Case:当前节点无子节点,返回空切片)。
| // BuildTreeRecursive 递归构建树形结构
// 每一层都需要线性扫描完整列表,时间复杂度 O(n^2)
func BuildTreeRecursive(areas []*Area, parentID int) []*Area {
var tree []*Area
for _, area := range areas {
if area.ParentID == parentID {
area.Children = BuildTreeRecursive(areas, area.ID) // 递归挂载子节点
tree = append(tree, area)
}
}
return tree
}
// 调用:从 parentID=0 的顶级节点开始构建
tree := BuildTreeRecursive(flatData, 0)
|
方法二:哈希表(\(O(n)\))
递归方案的瓶颈在于:每处理一个节点都要线性扫描整个列表。优化思路是先用哈希表建立 ID → 节点 的映射,将子节点查找从 \(O(n)\) 降为 \(O(1)\),整体只需两次线性遍历。
| // BuildTreeHashMap 使用哈希表构建树形结构
// 两次线性遍历,时间复杂度 O(n)
func BuildTreeHashMap(areas []*Area) []*Area {
var roots []*Area
areaMap := make(map[int]*Area, len(areas))
// 第一次遍历:建立 ID → 节点 的映射
for _, area := range areas {
areaMap[area.ID] = area
}
// 第二次遍历:将每个节点挂载到其父节点上
for _, area := range areas {
if area.ParentID == 0 {
roots = append(roots, area) // 顶级节点直接收集
continue
}
if parent, ok := areaMap[area.ParentID]; ok {
parent.Children = append(parent.Children, area)
}
}
return roots
}
|