Go 刷题清单
哈希表
| func twoSum(nums []int, target int) []int {
// 哈希表记录出现的元素及索引
// 遍历 nums,如果 target - num 在哈希表中,返回索引
// 否则将 num 加入哈希表
seen := map[int]int{}
for i, num := range nums {
if prevIndex, ok := seen[target-num]; ok {
return []int{prevIndex, i}
}
seen[num] = i
}
return []int{}
}
|

排序解法
|

计数解法
|
| // 排序解法
// Time: O(m*nlogn), Space: O(m*n)
func groupAnagrams(strs []string) [][]string {
groups := map[string][]string{}
for _, str := range strs {
bytes := []byte(str)
slices.Sort(bytes)
key := string(bytes)
groups[key] = append(groups[key], str)
}
result := make([][]string, 0, len(groups))
for _, group := range groups {
result = append(result, group)
}
return result
}
|
| // 计数解法
// Time: O(m*n), Space: O(m*n)
func groupAnagrams(strs []string) [][]string {
groups := map[[26]int][]string{}
for _, str := range strs {
count := [26]int{}
for _, ch := range str {
count[ch-'a']++
}
groups[count] = append(groups[count], str)
}
result := make([][]string, 0, len(groups))
for _, group := range groups {
result = append(result, group)
}
return result
}
|
双指针
| func lengthOfLongestSubstring(s string) int {
// 哈希表记录出现的元素及索引
// 哈希表出现的元素,left 移动到哈希表中索引 +1 位置,否则右指针右移扩大窗口
seen := map[byte]int{}
left, right, maxWin := 0, 0, 0
for right < len(s) {
if prevIndex, ok := seen[s[right]]; ok {
left = prevIndex + 1
}
seen[s[right]] = right
right++
maxWin = max(maxWin, right-left)
}
return maxWin
}
|
| func threeSum(nums []int) [][]int {
if len(nums) < 3 {
return nil
}
sort.Ints(nums)
ans := [][]int{}
// 先固定第一个数
for i := 0; i < len(nums)-2; i++ {
// 提前剪枝:如果第一个数已经大于0,后面都是正数,不可能和为0
if nums[i] > 0 {
break
}
if i > 0 && nums[i] == nums[i-1] {
continue // 跳过重复的第一个数
}
// 用双指针让剩余两数之和与第一个数的和为0
left, right := i+1, len(nums)-1
for left < right {
sum := nums[i] + nums[left] + nums[right]
// 注意此时已经排序
if sum < 0 { // 和太小,需要右移靠近较大数
left++
} else if sum > 0 { // 和太大,需要左移靠近较小数
right--
} else { // 和为 0
ans = append(ans, []int{nums[i], nums[left], nums[right]})
// 跳过重复的第二个数
for left < right && nums[left] == nums[left+1] {
left++
}
// 跳过重复的第三个数
for left < right && nums[right] == nums[right-1] {
right--
}
left++
right--
}
}
}
return ans
}
|
由于本题查找最长回文子串,我们并不清楚回文边界,因此 无法使用对撞指针,只能用回文中心对称的特点,从中心向两侧扩展求解。
| // Time: O(n²), Space: O(1)
func longestPalindrome(s string) string {
start, maxLen := 0, 0
// 从中心向两侧扩展,返回回文长度
expand := func(l, r int) {
for l >= 0 && r < len(s) && s[l] == s[r] {
l--
r++
}
// 此时 [l+1, r-1] 是回文
if r-l-1 > maxLen {
start = l + 1
maxLen = r - l - 1
}
}
for i := range s {
// 无法预知以某个位置为中心的最长回文是奇数还是偶数长度,因此需要同时遍历两种情况,取最长的那个
expand(i, i) // 奇数长度回文(如 "aba")
expand(i, i+1) // 偶数长度回文(如 "abba")
}
return s[start : start+maxLen]
}
|
题目解释:将数组视为一个数字,在所有排列中找到恰好比当前排列大的下一个排列;若已是最大排列,则回绕到最小排列。
nums = [1,2,3]:对应数字 123,所有排列按大小排序为 123 → 132 → 213 → …,下一个排列为 [1,3,2]nums = [3,2,1]:对应数字 321,已是最大排列,回绕到最小排列 [1,2,3]
解题思路:
- 从右往左,找到第一个满足
nums[k] < nums[k+1] 的位置 k(即第一个"下降点")。若不存在,说明已是最大排列,直接翻转整个数组即可。(可以通过折线图可视化查找过程)
- 再从右往左,找到第一个满足
nums[l] > nums[k] 的位置 l。
- 交换
nums[k] 与 nums[l]。
- 翻转
nums[k+1:],使其从降序变为升序,得到恰好大一点的排列。
以 nums = [1,2,7,4,3,1] 为例:
- 找下降点:从右往左扫描,
nums[1]=2 < nums[2]=7,故 k=1
- 找交换点:从右往左找第一个大于 2 的数,
nums[4]=3,故 l=4
- 交换:
nums = [1,3,7,4,2,1]
- 翻转
nums[2:]:nums = [1,3,1,2,4,7] ✅
| // Time: O(n), Space: O(1)
func nextPermutation(nums []int) {
// 从右往左找到第一个下降点 i
i := len(nums) - 2
for i >= 0 && nums[i] >= nums[i+1] {
i--
}
if i >= 0 {
// 从右往左找到第一个大于 nums[i] 的数 j
j := len(nums) - 1
for nums[j] <= nums[i] {
j--
}
// 交换 i 和 j
nums[i], nums[j] = nums[j], nums[i]
}
// 反转 i 之后的部分
left, right := i+1, len(nums)-1
for left < right {
nums[left], nums[right] = nums[right], nums[left]
left++
right--
}
}
|
双指针倒序填充
| // Time: O(m+n), Space: O(1)
func merge(nums1 []int, m int, nums2 []int, n int) {
p1, p2, tail := m-1, n-1, m+n-1
// 只需检查 p2 >= 0,因为 nums2 处理完后,nums1 剩余元素已在正确位置
for p2 >= 0 {
if p1 >= 0 && nums1[p1] > nums2[p2] {
nums1[tail] = nums1[p1]
p1--
} else {
nums1[tail] = nums2[p2]
p2--
}
tail--
}
}
|
| // Time: O(n+m), Space: O(1)
func compareVersion(version1, version2 string) int {
n, m := len(version1), len(version2)
i, j := 0, 0
for i < n || j < m {
x := 0
for i < n && version1[i] != '.' {
x = x*10 + int(version1[i]-'0')
i++
}
i++ // 跳过点号
y := 0
for j < m && version2[j] != '.' {
y = y*10 + int(version2[j]-'0')
j++
}
j++ // 跳过点号
if x > y {
return 1
}
if x < y {
return -1
}
}
return 0
}
|
链表
| func reverseList(head *ListNode) *ListNode {
var prev *ListNode
// 暂存、反转、移动
for head != nil {
next := head.next
head.Next = prev
prev = head
head = next
}
return prev
}
|
头插法,将每个要反转的节点连接到 prev 后
| func reverseBetween(head *ListNode, left, right int) *ListNode {
dummy := &ListNode{Next: head}
prev := dummy
for range left - 1 {
prev = prev.Next
}
cur := prev.Next
for range right - left {
next := cur.Next
cur.Next = next.Next
next.Next = prev.Next
prev.Next = next
}
return dummy.Next
}
|
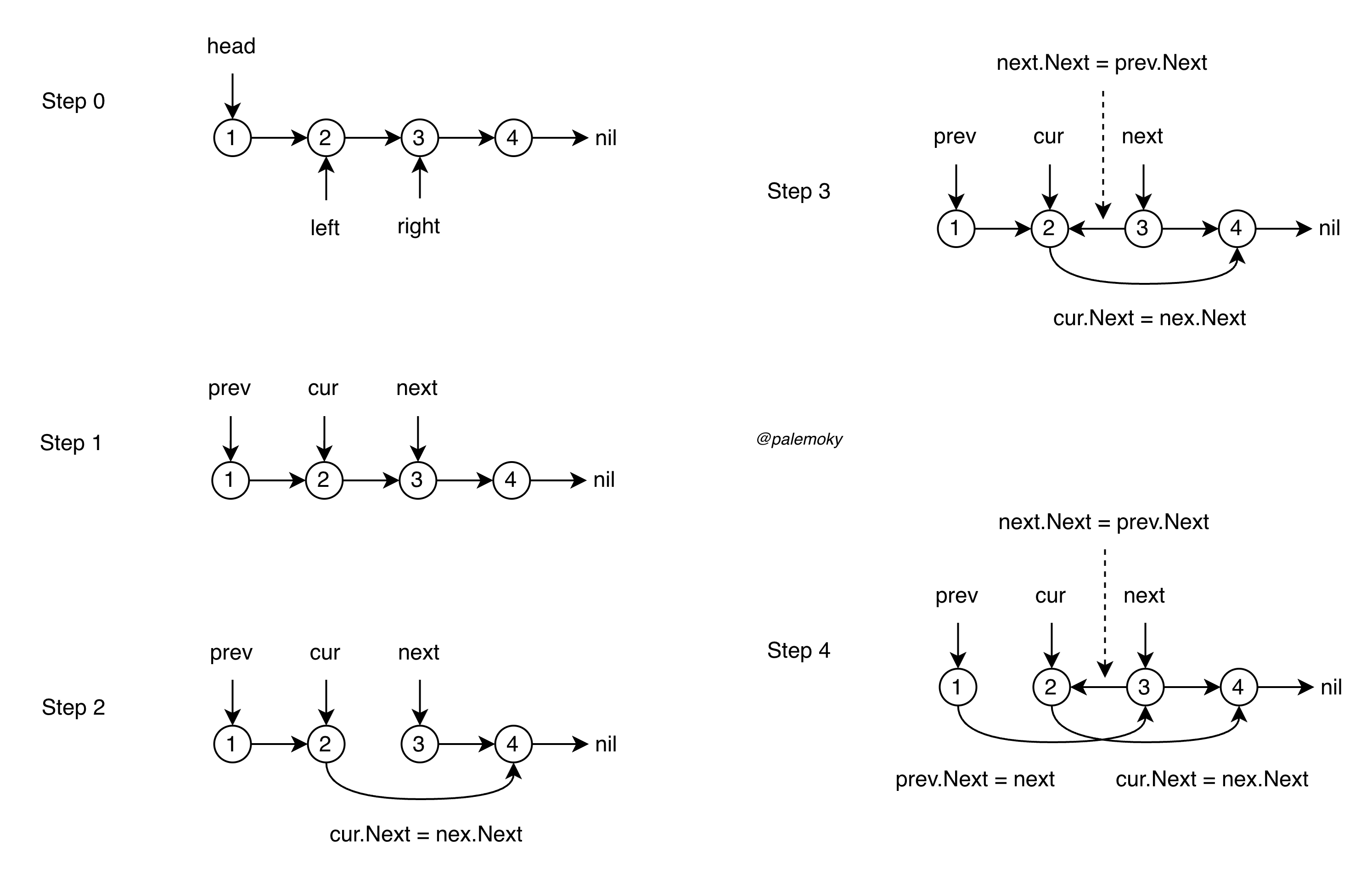
分组+局部反转
| func reverseKGroup(head *ListNode, k int) *ListNode {
dummy := &ListNode{Next: head}
prev := dummy
for {
tail := prev
for range k {
tail = tail.Next
if tail == nil {
return dummy.Next
}
}
nextGroup := tail.Next
// 局部反转链表
cur := prev.Next
for range k - 1 {
next := cur.Next
cur.Next = next.Next
next.Next = prev.Next
prev.Next = next
}
cur.Next = nextGroup
prev = cur
}
}
|
快慢指针解法:快指针走两步,慢指针走一步,相遇则有环
| func hasCycle(head *ListNode) bool {
slow, fast := head, head
for fast != nil && fast.Next != nil {
slow, fast = slow.Next, fast.Next.Next
if slow == fast {
return true
}
}
return false
}
|
| func detectCycle(head *ListNode) *ListNode {
seen := map[*ListNode]struct{}{}
for head != nil {
if _, ok := seen[head]; ok {
return head
}
seen[head] = struct{}{}
head = head.Next
}
return nil
}
|
| func mergeSortedTwoLists(l1, l2 *ListNode) *ListNode {
dummy := &ListNode{}
current := dummy
// 注意该遍历需同时操作3个链表
for l1 != nil && l2 != nil { // 注意是 &&
if l1.Val < l2.Val { // 将较小的值挂载在新链表上
current.Next = l1
l1 = l1.Next // 移动原链表
} else {
current.Next = l2
l2 = l2.Next
}
current = current.Next // 移动新链表
}
// 将链表剩余部分挂载,同时处理原链表为空
if l1 != nil {
current.Next = l1
} else {
current.Next = l2
}
// 注意返回的是 dummy.Next
return dummy.Next
}
|
双向链表 + 哈希表
| type Node struct {
key, value int
prev, next *Node
}
type LRUCache struct {
capacity int
cache map[int]*Node // 哈希表:key -> 链表节点
head *Node // 虚拟头节点(最近使用)
tail *Node // 虚拟尾节点(最久未使用)
}
func Constructor(capacity int) LRUCache {
lru := LRUCache{
capacity: capacity,
cache: make(map[int]*Node),
head: &Node{},
tail: &Node{},
}
lru.head.next = lru.tail
lru.tail.prev = lru.head
return lru
}
func (lc *LRUCache) Get(key int) int {
if node, exists := lc.cache[key]; exists {
// 将节点移到头部(标记为最近使用)
lc.moveToHead(node)
return node.value
}
return -1
}
func (lc *LRUCache) Put(key, value int) {
if node, exists := lc.cache[key]; exists {
// 更新已存在的节点
node.value = value
lc.moveToHead(node)
} else {
// 创建新节点
newNode := &Node{key: key, value: value}
lc.cache[key] = newNode
lc.addToHead(newNode)
// 检查容量,必要时删除最久未使用的节点
if len(lc.cache) > lc.capacity {
removed := lc.removeTail()
delete(lc.cache, removed.key)
}
}
}
// 辅助方法:将节点添加到头部
func (lc *LRUCache) addToHead(node *Node) {
node.prev = lc.head
node.next = lc.head.next
lc.head.next.prev = node
lc.head.next = node
}
// 辅助方法:移除节点
func (lc *LRUCache) removeNode(node *Node) {
node.prev.next = node.next
node.next.prev = node.prev
}
// 辅助方法:将节点移到头部
func (lc *LRUCache) moveToHead(node *Node) {
lc.removeNode(node)
lc.addToHead(node)
}
// 辅助方法:移除尾部节点
func (lc *LRUCache) removeTail() *Node {
node := lc.tail.prev
lc.removeNode(node)
return node
}
|
二叉树
遍历方式
队列+双层循环(外循环控制深度,内循环控制宽度)
| func levelOrder(root *TreeNode) [][]int {
ans := [][]int{}
if root == nil {
return ans
}
queue := []*TreeNode{root}
for len(queue) > 0 {
level := make([]int, 0, len(queue))
for range len(queue) {
node := queue[0]
queue = queue[1:]
level = append(level, node.Val)
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
ans = append(ans, level)
}
return ans
}
|
栈:先压右再压左
| func preOrderTraversal(root *TreeNode) []int {
ans := []int}{}
if root == nil {
return ans
}
stack := []*TreeNode{root}
for len(stack) > 0 {
node := stack[len(stack)-1]
stack = stack[:len(stack)-1]
ans = append(ans, node.Val)
// 因为栈是先进后出,所以先压右节点
if node.Right != nil {
stack = append(stack, node.Right)
}
if node.Left != nil {
stack = append(stack, node.Left)
}
}
return ans
}
|
栈:一路向左,先处理完左子树再处理右子树
| func inOrderTraversal(root *TreeNode) []int {
ans := []int{}
stack := []*TreeNode{}
curr := root
for curr != nil || len(stack) > 0 {
// 把节点一路向左压入栈
for curr != nil {
stack = append(stack, curr)
curr = curr.Left
}
// 开始倒序处理栈中的节点(即从下往上遍历树)
curr = stack[len(stack)-1]
stack = stack[:len(stack)-1]
ans = append(ans, curr.Val)
// 左子树处理完处理右子树
curr = curr.Right
}
return ans
}
|
后序遍历的迭代实现由中序遍历演化而来,主要区别在于后序遍历需在右子树遍历完成后才处理根节点。因此,引入 prev 指针用于记录历史状态,防止右子树被重复访问。这一机制类似于回溯算法中利用 used[] 数组来标记路径是否已被使用。
Note
以 [1,2,3,4,5] 为例,
第 1 次遇到节点 2(检查阶段):
| // 一路向左:1 → 2 → 4
stack = [1, 2, 4]
// 访问完4后,回到节点2
curr = stack[1] = 2 // ← 第1次遇到节点2
// 判断
if curr.Right == nil || curr.Right == prev {
// 2.Right = 5, prev = 4
// 5 != 4 不满足条件
} else {
curr = curr.Right // ← 转向右子树5,暂时不访问2
}
|
第 2 次遇到节点 2(访问阶段):
| // 访问完5后,再次回到节点2
stack = [1, 2]
curr = stack[1] = 2 // ← 第2次遇到节点2
// 判断
if curr.Right == nil || curr.Right == prev {
// 2.Right = 5, prev = 5
// 5 == 5 ✅ 满足条件(右子树已访问)
stack = [1]
nums = append(nums, 2) // ← 现在才真正访问节点2
prev = 2
curr = nil
}
|
每个节点可能被访问两次:
| func postOrderTraversal(root *TreeNode) []int {
ans := []int{}
stack := []*TreeNode{}
var prev *TreeNode
curr := root
for curr != nil || len(stack) > 0 {
for curr != nil {
stack = append(stack, curr)
curr = curr.Left
}
// 查看栈顶不弹出
curr = stack[len(stack)-1]
if curr.Right == nil || curr.Right == prev {
stack = stack[:len(stack)-1]
ans = append(ans, curr.Val)
prev = curr
curr = nil
} else {
curr = curr.Right
}
}
return ans
}
|
| func traversal(root *TreeNode) []int {
if root == nil {
return []int{}
}
// Preorder: 根 -> 左 -> 右
// nums := []int{root.Val}
// nums = append(nums, traversal(root.Left)...)
// nums = append(nums, traversal(root.Right)...)
// Inorder: 左 -> 根 -> 右
nums := traversal(root.Left)
nums = append(nums, root.Val)
nums = append(nums, traversal(root.Right)...)
// Postorder: 左 -> 右 -> 根
// nums := traversal(root.Left)
// nums = append(nums, traversal(root.Right)...)
// nums = append(nums, root.Val)
return nums
}
|
后序遍历题目
当节点需要依赖左右子树的信息时,使用后序遍历
后序遍历的递归解法:先钻到最底下,在返回时再做处理
| func maxDepth(root *TreeNode) int {
if root == nil {
return 0
}
left := maxDepth(root.Left)
right := maxDepth(root.Right)
return max(left, right) + 1
}
|
平衡树就是左右子树高度差不超过 1,所以要基于后序遍历的树深度来求解
| func abs(x int) int {
if x < 0 {
return -x
}
return x
}
func isBalanced(root *TreeNode) bool {
return checkHeight(root) != -1
}
// 返回树的高度,如果不平衡则返回 -1
// 后序遍历:先递归左右子树,返回时处理当前节点
func checkHeight(root *TreeNode) int {
if root == nil {
return 0
}
// 后序遍历:先检查左子树
leftHeight := checkHeight(root.Left)
if leftHeight == -1 {
return -1 // 左子树不平衡,提前终止
}
// 后序遍历:再检查右子树
rightHeight := checkHeight(root.Right)
if rightHeight == -1 {
return -1 // 右子树不平衡,提前终止
}
// 返回时处理:检查当前节点是否平衡
if abs(leftHeight-rightHeight) > 1 {
return -1 // 当前节点不平衡
}
// 返回当前节点的高度(自底向上汇总信息)
return max(leftHeight, rightHeight) + 1
}
|
| func diameterOfBinaryTree(root *TreeNode) int {
maxDiameter := 0
var depth func(*TreeNode) int
depth = func(node *TreeNode) int {
if node == nil {
return 0
}
// 后序遍历:先递归计算左右子树的深度
leftDepth := depth(node.Left)
rightDepth := depth(node.Right)
// 当前节点的直径 = 左子树深度 + 右子树深度
maxDiameter = max(maxDiameter, leftDepth+rightDepth)
// 计算当前节点的深度
return max(leftDepth, rightDepth) + 1
}
depth(root)
return maxDiameter
}
|
与树的直径类似,对于每个节点,路径和 = 左子树贡献 + 右子树贡献 + 当前节点值
| func maxPathSum(root *TreeNode) int {
maxSum := math.MinInt32 // 初始化为最小值,因为节点值可能为负
var maxGain func(*TreeNode) int
maxGain = func(node *TreeNode) int {
if node == nil {
return 0
}
// 后序遍历:先递归计算左右子树的最大贡献
// 如果子树贡献为负,则不选择该子树(取 0)
leftGain := max(maxGain(node.Left), 0)
rightGain := max(maxGain(node.Right), 0)
// 以当前节点为"拐点"的路径和
// 路径和 = 左子树贡献 + 右子树贡献 + 当前节点值
currentPathSum := leftGain + rightGain + node.Val
maxSum = max(maxSum, currentPathSum)
// 返回给父节点的最大贡献:只能选择左或右其中一条路径
// 贡献 = 当前节点值 + max(左子树贡献, 右子树贡献)
return node.Val + max(leftGain, rightGain)
}
maxGain(root)
return maxSum
}
|

最近公共祖先示例
|

LCA 判断逻辑
|
| func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
// 递归终止条件:
// 1. 搜到底了(nil)
// 2. 找到目标节点(p 或 q)
if root == nil || root == p || root == q {
return root
}
// 后序遍历:先递归左右子树
left := lowestCommonAncestor(root.Left, p, q)
right := lowestCommonAncestor(root.Right, p, q)
// 根据左右子树的返回值判断 LCA 位置
// 情况1:p 和 q 分散在左右两侧 → 当前节点就是 LCA
if left != nil && right != nil {
return root
}
// 情况2:p 和 q 都在左子树 → 返回左子树的结果
if left != nil {
return left
}
// 情况3:p 和 q 都在右子树(或右子树找到一个)→ 返回右子树的结果
return right
}
|
由于 BST 的有序性,其解法与普通的 LCA 相似:如果 \(p\) 和 \(q\) 都小于当前节点,则 LCA 在左子树;如果 \(p\) 和 \(q\) 都大于当前节点,则 LCA 在右子树;否则当前节点就是 LCA。
| // 迭代解法(推荐)
// Time: O(h), Space: O(1)
func lowestCommonAncestorIterative(root, p, q *TreeNode) *TreeNode {
for root != nil {
if p.Val < root.Val && q.Val < root.Val {
root = root.Left
} else if p.Val > root.Val && q.Val > root.Val {
root = root.Right
} else {
return root
}
}
return nil
}
|
| // 递归解法
// Time: O(h), Space: O(h)
func lowestCommonAncestorRecursive(root, p, q *TreeNode) *TreeNode {
if p.Val < root.Val && q.Val < root.Val {
return lowestCommonAncestorRecursive(root.Left, p, q)
}
if p.Val > root.Val && q.Val > root.Val {
return lowestCommonAncestorRecursive(root.Right, p, q)
}
return root
}
|
中序遍历题目
前序遍历题目
当节点需要依赖左右子树的信息时,使用前序遍历,这样不仅代码简单,而且高效
层序遍历题目
| // Time: O(n), Space: O(n)
func zigzagLevelOrder(root *utils.TreeNode) [][]int {
result := [][]int{}
if root == nil {
return result
}
leftToRight := true
queue := []*utils.TreeNode{root}
for len(queue) > 0 {
levelSize := len(queue)
level := make([]int, levelSize)
for i := range levelSize {
node := queue[0]
queue = queue[1:]
// 根据方向决定插入位置
index := i
if !leftToRight {
index = levelSize - 1 - i
}
level[index] = node.Val
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
result = append(result, level)
leftToRight = !leftToRight
}
return result
}
|
| func rightSideView(root *TreeNode) []int {
ans := []int{}
if root == nil {
return ans
}
queue := []*TreeNode{root}
for len(queue) > 0 {
width := len(queue)
for i := range width {
node := queue[0]
queue = queue[1:]
// 只把每层的最后一个节点加入结果集
if i == width-1 {
ans = append(ans, node.Val)
}
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
}
return ans
}
|
| func minDepth(root *TreeNode) int {
if root == nil {
return 0
}
depth := 1 // 非空节点的最小深度为 1
queue := []*TreeNode{root}
for len(queue) > 0 {
for range len(queue) {
node := queue[0]
queue = queue[1:]
// 找到第一个叶子节点,立即返回
if node.Left == nil && node.Right == nil {
return depth
}
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
depth++
}
return depth
}
|
| // Time: O(n), Space: O(n)
func findBottomLeftValue(root *TreeNode) int {
firstNode := 0
queue := []*TreeNode{root}
for len(queue) > 0 {
for i := range len(queue) {
node := queue[0]
queue = queue[1:]
// 只记录每层的第一个节点
if i == 0 {
firstNode = node.Val
}
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
}
return firstNode
}
|
DFS
可用DFS、BFS、并查集3种解法,但推荐DFS
| // Time: O(m×n), Space: O(m×n) 递归栈
func numIslandsDFS(grid [][]byte) int {
if len(grid) == 0 {
return 0
}
count := 0
for i := range grid {
for j := range grid[0] {
if grid[i][j] == '1' {
count++
dfs(grid, i, j)
}
}
}
return count
}
func dfs(grid [][]byte, i, j int) {
// 边界检查
if i < 0 || i >= len(grid) || j < 0 || j >= len(grid[0]) || grid[i][j] == '0' {
return
}
// 标记为已访问
grid[i][j] = '0'
// 递归访问四个方向
dfs(grid, i-1, j) // 上
dfs(grid, i+1, j) // 下
dfs(grid, i, j-1) // 左
dfs(grid, i, j+1) // 右
}
|
堆/优先队列
栈
队列
二分查找
动态规划
回溯
贪心
递归
编写递归步骤:
- 明确输入输出
- 明确递归终止条件(什么时候触底反弹?)
- 明确递归处理逻辑(每层要做什么事?)
- 明确递归过程(下楼做还是返回做?)
图论


